Некорректное ведение журнала с системными логами характеризуется отсутствием последних записей о событиях в разделе «Системные логи».
Для восстановления ведения журнала с системными логами:
Перезапустите компоненты мобильной платформы на сервере или в кластере, если используется отказоустойчивый кластер на основе OKD/OCP:
контейнеры hyperhive_celeryworker_1, hyperhive_redis_1 на сервере мобильной платформы;
поды fmp-celeryworker, fmp-redis в кластере.
Проверьте объём выделенных системных ресурсов дискового пространства для Elasticsearch:
контейнер hyperhive_elasticsearch_1 на сервере мобильной платформы;
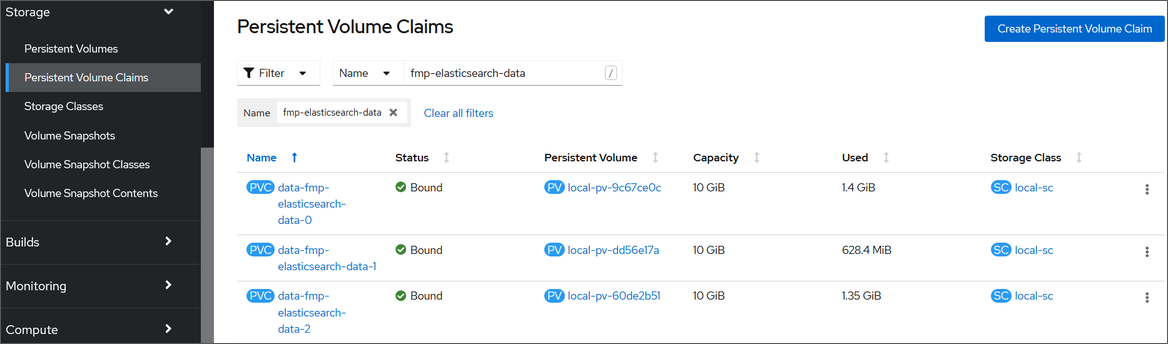
Persistent Volumes (PV) пода fmp-elasticsearch-data в кластере. Для этого в приложении OKD откройте подраздел «Storage > Persistent Volume Claims»:
В столбце «Capacity» содержится объём выделенных системных ресурсов, в столбце «Used» - объём используемых системных ресурсов.
При необходимости добавьте объём потребления системных ресурсов для контейнера hyperhive_elasticsearch_1 на сервере мобильной платформы с помощью средств операционной системы или виртуализации.
Для добавления объёма потребления системных ресурсов PV пода fmp-elasticsearch-data в кластере:
Важно. Выберите время с минимальной пользовательской нагрузкой на кластер, так как в процессе добавления объёма потребления системных ресурсов блокируется выполнение фоновых задач. Также при необходимости экспортируйте журнал с логами в файл. После выполнения действий с подом системные логи будут удалены.
Остановите запись логов в Elasticsearch. Для этого уменьшите количество подов fmp-celeryworker до 0.
Уменьшите количество подов fmp-elasticsearch-data до 0.
Определите, какие PV используются подами fmp-elasticsearch-data и удалите для них Persistent Volume Claim (PVC).
Добавьте объём освобождённых PV до 30G.
Пропишите storageClass с именем es-data для увеличенных PV.
Пропишите storageClass с именем es-data для подов fmp-elasticsearch-data:
измените yaml-файл с помощью приложения OKD (для применения изменений в текущем релизе) в соответствии со структурой:
spec:
volumeClaimTemplates:
spec:
storageClassName: es-data
измените файл values.production.yaml (для применения изменений в следующих обновлениях/переустановках релиза) в соответствии со структурой:
elasticsearch:
data:
persistence:
storageClass: es-data
Добавьте количество подов fmp-elasticsearch-data до 3 и убедитесь, что все поды запускаются и успешно создают новые PVC на основе обновлённых PV.
Подготовьте Elasticsearch. Для этого перейдите в терминал одного из подов fmp-dashboard и запустите скрипт init.sh из любого места.
Возобновите запись логов в Elasticsearch. Для этого верните количество подов fmp-celeryworker до 1.
После выполнения действий будет восстановлено ведение журнала с системными логами.
См. также: