В этой статье:
Загрузка данных в файловый кеш
Изменение и сохранение данных при использовании файлового кеша
Консоль управления файловым кешем
Логирование выполняемых действий
Расширенные способы и режимы обработки данных
Работа с файловым кешем
При использовании файлового кеша в «Форсайт. Аналитическая платформа» необходимый набор данных хранится на жестком диске, и информация по мере необходимости (в зависимости от запросов пользователей) фрагментами подгружается в оперативную память.
Файловый кеш поддерживает многопоточную многопользовательскую работу, оптимизируя расчёты распараллеливанием нагрузки по процессорам, обеспечивая корректность данных при множественных обращениях к одному кешу. При многопользовательской работе экземпляр прокешированных данных в памяти находится только один, а доступ разделяется на уровне сессий пользователей.
Для получения подробной информации о работе с файловым кешем в Fore обратитесь к статье «Работа с файловым кешем в Fore».
Загрузка данных в файловый кеш
Загрузка данных в файловый кеш возможна при использовании консоли управления кешированием данных многомерных кубов.
Все необходимые данные заранее выгружаются (кешируются) из базы данных в файлы на жестком диске (файловый кеш).
При формировании кеша данные можно сохранить:
все данные куба;
данные по определенной отметке в кубе.
Выбор варианта загрузки данных в файловый кеш зависит от решаемых задач и структуры источников данных. Например, формирование кеша по данным определенной отметки куба целесообразно, если достоверно известно, что в основном синхронизация с СУБД производится по ограниченному набору исходных данных. Также формирование записей кеша по частичной отметке будет более оптимальным вариантом, в случае если куб параметрический и значение параметра некоторым образом ограничивает набор данных куба. В большинстве случаев при работе с относительно небольшими кубами более оптимальным вариантом будет создание кеша по полной отметке.
Фрагменты данных по мере необходимости подгружаются из файлового кеша в оперативную память, при достижении установленного лимита памяти более свежие выборки замещают неиспользуемые. Система гарантирует, что независимо от объёма прокешированных данных объём занятной файловым кешем оперативной памяти не превысит указанный лимит. Слишком сильное ограничение объёма предоставляемой оперативной памяти повлечёт снижение производительности, особенно при кешировании данных, хотя работоспособность системы будет обеспечена.
Гибридный режим использования кеша задаётся кешированием куба по заданной отметке. При этом прокешированные данные будут оперативно извлекаться из кеша, а оставшаяся часть данных будет извлекаться обычными SQL-запросами. Это позволяет сократить объём кешируемых данных, реализовав раздельное хранение «горячих» и «холодных» данных.
Изменение и сохранение данных при использовании файлового кеша
Изменение данных в файловом кеше происходит при сохранении изменённых данных в куб – при этом данные записываются одновременно в SQL-источник и в файловый кеш. При необходимости возможно настроить работу, чтобы сохранение данных в SQL-источник при этом не производилось – тогда кеш работал бы с максимальной производительностью как на чтение, так и на запись, в этом случае синхронизация данных с SQL-источником проводится вручную с помощью консоли.
При изменении и сохранении данных средствами «Форсайт. Аналитическая платформа» вся информация обновляется и в файловом кеше, и в таблицах базы данных автоматически, в соответствии с настройками.
Если данные в исходной таблице, на которой построен прокешированный куб, изменились извне системы, например, прямым пополнением через SQL, то можно явно обновить кеш через вызов IInMemManager.UpdateBySelection, вызываемый из Fore-модуля, либо через планировщик. При этом указывается отметка, в рамках которой будет производиться обновление данных. Например, можно обновить данные за последний день, указав соответствующий элемент календарного измерения.
При сохранении данных в файловый кеш автоматически происходит инкрементальный пересчёт хранимых агрегатов и свёрток, связанных с прокешированным кубом. При этом обновляется только та часть агрегатов, которая зависит от изменённых ячеек. При обращении к хранимым агрегатам из отчётов всегда выводятся актуальные данные.
Агрегация данных
Файловый кеш поддерживает агрегацию данных для кубов с иерархическими измерениями. Агрегация должна быть настроена на странице «Агрегация» мастера стандартного куба.
Для задания режима расчета агрегатов с использованием файлового кеша, необходимо настроить значение параметра AggrType одним из следующих способов:
при использовании конкретного режима расчета агрегатов для всех кубов с файловым кешем из репозитория, параметр задаётся в файле settings.xml или системном реестре сервера;
при использовании собственного режима агрегации конкретного куба, параметр задаётся в консоли управления кешированием данных;
В файловом кеше имеется несколько способов расчёта иерархической агрегации:
Агрегация по запросу. Для включения агрегации задайте параметр AggrType=request. Система может рассчитывать агрегаты по запросу при каждом обращении. Файловый кеш использует производительные параллельные алгоритмы расчёта агрегации, но при кешировании таким способом агрегации больших объёмов данных возможны заметные задержки;
Полная хранимая агрегация. Для включения агрегации задайте параметр AggrType=full. Способ используется по умолчанию. Система может полностью предвычислять агрегаты: рассчитать, хранить и актуализировать все агрегатные данные по иерархии куба. При открытии отчёта не возникает задержек на вычисления агрегатов, так как они уже в готовом виде берутся из кеша. При изменении данных исходного куба пересчитывается только необходимый фрагмент данных куба, что обеспечивает высокую скорость актуализации кеша агрегатов. Необходимо учитывать, что при больших объёмах данных будет использоваться большой объём занимаемой дисковой памяти и начальный расчёт полного объёма агрегатов займёт длительное время, так как объём агрегатов растёт по декартовому произведению по объёму элементов измерений куба;
Частично-хранимая агрегация. Система может предвычислять и хранить часть агрегатов, а остальные считать по запросу при каждом обращении. Это позволяет регулировать степень хранения агрегатов, выбирая оптимальную схему хранения и обработки агрегированных данных.
Для настройки хранимых уровней агрегатов задайте значение параметра StoredLevels.
При значении StoredLevels=1;1, что соответствует значению параметра AggrType=levels, в файловый кеш будут сохраняться агрегаты в первом, третьем и далее уровнях иерархических измерений куба, считая от листьевых элементов, а агрегаты второго, четвертого и далее уровней будут рассчитываться по запросу:
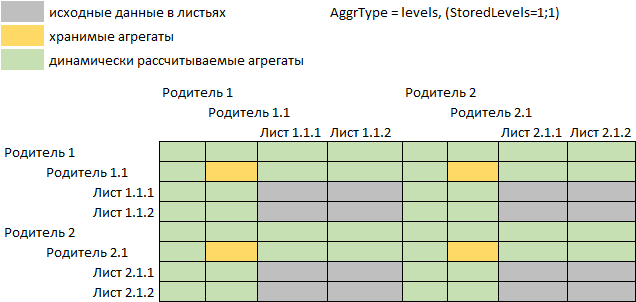
При значении StoredLevels=2;1 в файловый кеш будут сохраняться агрегаты во втором, четвертом и далее уровнях иерархических измерений куба, считая от листьевых элементов, а агрегаты первого, третьего и далее уровней будут рассчитываться по запросу:
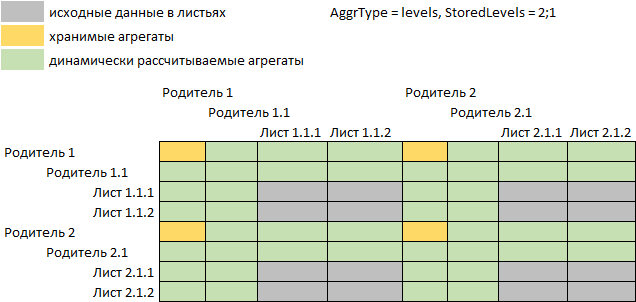
Если требуется дополнительно хранить значения «полуагрегатных» точек, у которых часть агрегируемых измерений относится к уровням иерархии, а часть – листьевые элементы, то задайте параметр AggrType=levels_semi либо дополнительно к параметру StoredLevels задайте параметр StoredSemiAggr=true:
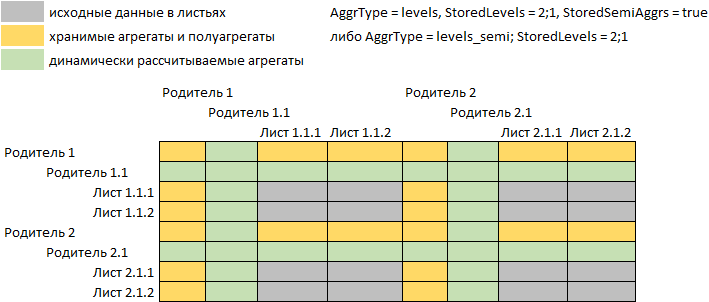
Частично-хранимых режимы агрегации будут работать только в условиях следующих ограничений:
используется метод агрегации «Сумма»;
настройки уровней агрегации одинаковы по всем уровням и по всем измерениям;
используется только основной механизм агрегации.
При выполнении этих ограничений применяется отдельный производительный режим агрегации, который заметно увеличит производительность обработки данных даже без применения частично-хранимого способа расчёта.
Физически рассчитанные и хранимые в файловом кеше агрегаты хранятся не в исходной матрице, а в отдельных файлах данных, которые совмещаются с исходными в результате выполнения запроса. Таким образом сохраняется возможность открывать куб с различными вариантами агрегации – например, применением альтернативных иерархий.
Переменный кеш
Если в кубе настроена агрегация по заданной отметке, то значения агрегатов зависят от заданной при агрегации отметки, и поэтому их невозможно рассчитать заранее для всего куба – только для каждого отдельного обращения. Если настроен режим хранимой агрегации, то для каждой новой заданной отметки будет рассчитана хранимая агрегация, записана в виде файлов, которые будут переиспользованы при последующих обращениях. То же самое относится и к вычислению свёрток - они также вычисляются для отметки на фиксированных измерениях. Эта часть кеша по отметке является переменной и может разрушаться и перестраиваться системой при вычислении агрегатов без потери работоспособности.
При интенсивном использовании инструментов отчётности объём переменной части кеша может стать слишком большим. Для ограничения размера диска, который занят переменными кешами, используйте параметр CacheLimitMb. Он позволяет задать максимально допустимый объём переменной части кеша, и при его превышении система удаляет самые редкоиспользуемые по дате последнего обращения из кешей по отметке.
Консоль управления файловым кешем
Для запуска консоли выполните команду  «Кеширование кубов» на боковой панели
навигатора
объектов. После чего на отдельной вкладке браузера
будет открыта страница с адресом в формате:
«Кеширование кубов» на боковой панели
навигатора
объектов. После чего на отдельной вкладке браузера
будет открыта страница с адресом в формате:
http://<IP-адрес или DNS-имя сервера>/fp10.x/app/cache.html#repo=<идентификатор репозитория>
Примечание. Для работы с консолью управления файловым кешем в репозитории должно быть установлено расширение «Кеш кубов».
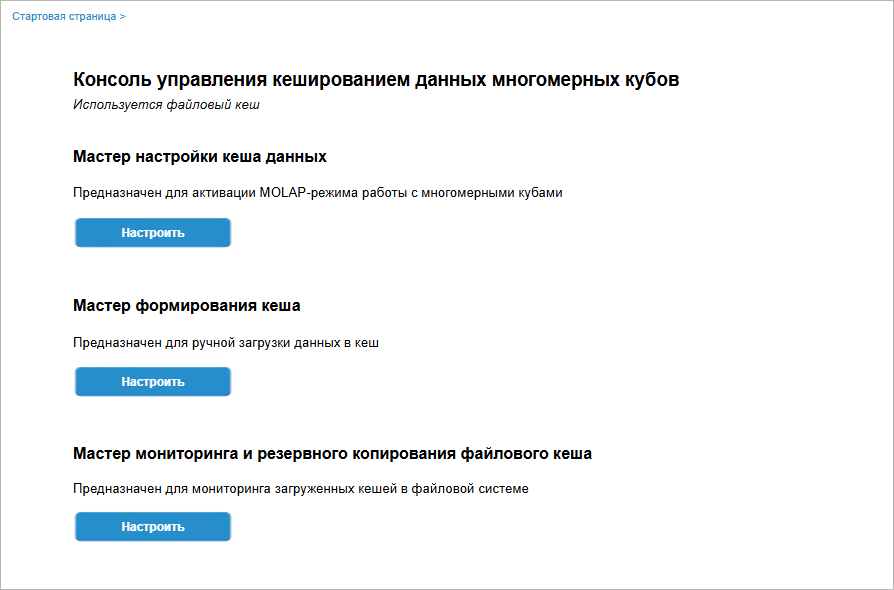
Доступны мастера:
Для начала работы с мастером нажмите кнопку «Настроить» в области на стартовой странице консоли. После выполнения действия будет открыта страница соответствующего мастера.
Мастер настройки кеша данных
Мастер настройки кеша данных предназначен для выбора объекта кеширования, настройки параметров файлового кеша для объекта и настройки записи.
Для начала работы с мастером настройки кеша данных нажмите кнопку «Настроить» в области мастера на стартовой странице консоли. После выполнения действия будет открыта страница «Модель кеша»:
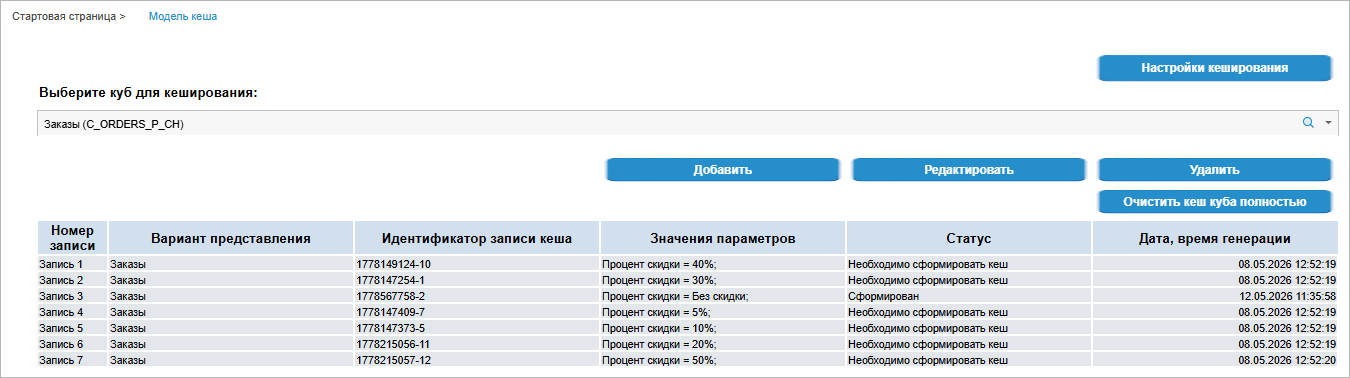
Доступны операции:
 Просмотр
системных настроек файлового кеша
Просмотр
системных настроек файлового кеша

 «
«
Редактирование
настроек кеширования куба


Мастер формирования кеша
Мастер формирования кеша данных предназначен для загрузки данных в кеш.
Для начала работы с мастером формирования кеша данных нажмите кнопку «Настроить» в области мастера на стартовой странице консоли. После выполнения действия будет открыта страница «Формирование кеша»:
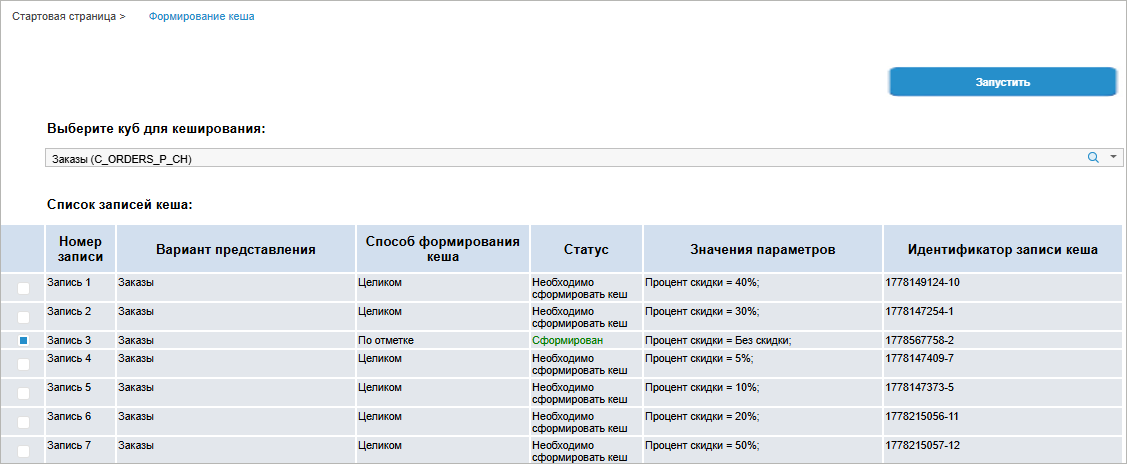
Доступны операции:


Мастер мониторинга и резервного копирования файлового кеша
Мастер мониторинга и резервного копирования файлового кеша предназначен для отслеживания всех записей кеша, очистки и загрузки данных кеша в СУБД.
Для начала работы с мастером мониторинга и резервного копирования файлового кеша нажмите кнопку «Настроить» в области мастера на стартовой странице консоли. После выполнения действия будет открыта страница «Мониторинг и резервное копирование»:
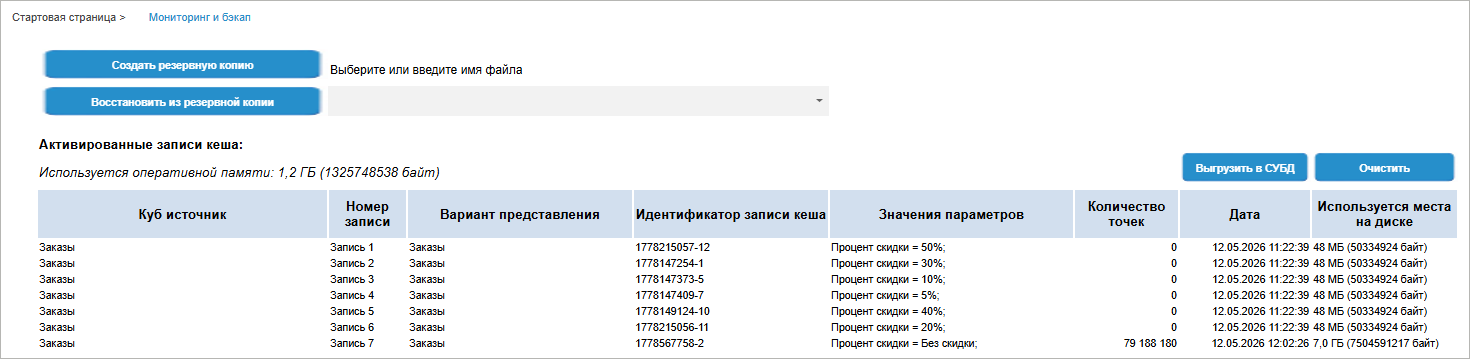
На странице будут отображена таблица записей кеша «Активированные записи кеша», которые в текущий момент загружены в файловой системе и количество используемой оперативной памяти.
Доступные операции:
Восстановление
из резервной копии
Логирование выполняемых действий
При работе с консолью управления кешем данных осуществляется логирование действий, которые выполняет пользователь. При первом открытии консоли внутри расширения «Кеш кубов» в папке «Служебные объекты» будут созданы таблицы для хранения лога. Запуск консоли должен осуществляться пользователем, который является администратором репозитория.
Создаются следующие таблицы:
Журнал экземпляра кеша (CACHE_ITEM_TABLE). Содержит информацию о кубах, их вариантах отображения и набор значений параметров, для которых созданы экземпляры кеша;
Журнал прогрева экземпляра кеша (CACHE_WARMING_TABLE). Содержит информацию о списке записей кеша, отметку, которая использовалась при создании записей;
Журнал загрузки данных в кеш (CACHE_LOG_TABLE). Содержит полную информацию о загрузках данных в кеш:
Даты и время фиксации записей в журнал;
Статус загрузки;
Информацию о потоках, количество загруженных точек с данными;
Информацию, позволяющую идентифицировать пользователя, который выполнял загрузку.
Примечание. Для корректного создания таблиц, в которых хранится лог работы с кешем, репозиторий должен быть создан на базе СУБД PostgreSQL, и в репозитории должна быть настроена база данных по умолчанию.
По умолчанию доступ к таблицам будет у всех пользователей репозитория. При необходимости администратор должен настроить права доступа в соответствии с требованиями разрабатываемой системы.
Расширенные способы и режимы обработки данных
При использовании файлового кеша на MOLAP-сервере появляется возможность использования различных способов обработки данных и аналитических средств:
Ассоциативный анализ измерений
Позволяет выполнять запросы, рассчитывающие элементы отметки измерений, по которым в кешированной матрице имеются данные, но которые ещё не отображены. Задачей ассоциативного анализа является определение связей между измерениями для эффективного выбора записей из большого объема данных. Ассоциативный анализ используется в информационных панелях и регламентных отчётах. Для включения ассоциативного анализа задайте значение параметра AllowAssoc=true в консоли управления кешированием данных многомерных кубов для конкретного куба или в файле settings.xml или в системном реестре для сервера. Если ассоциативный анализ не включен параметром, но выполняется запрос для его применения, то необходимые данные будут построены перед обработкой запроса, с некоторой задержкой по времени.
Динамическая агрегация
Позволяет агрегировать данные с помощью специальных отметок. Отметки задаются в специальном атрибуте справочника. Данным атрибутом справочника могут задаваться следующие динамические операции при агрегации дочернего уровня в вышестоящий:
+ - значения добавляются в агрегат;
- - значения вычитаются из агрегата;
~ – значения не учитываются в агрегате;
F[число] – значения умножаются на заданный весовой коэффициент, который является положительным числом. Например, задание F1.5 приведёт к увеличению значения в полтора раза;
N – пропуск обработки всего уровня.
В настройках куба необходимо указать, какой атрибут справочника будет использоваться для определения операций. Динамическая агрегация задаётся параметром DynAggrAttr в консоли управления кешированием данных многомерных кубов для конкретного куба или в файле settings.xml или в системном реестре для сервера.
Частичный кеш
Позволяет часть данных извлекать из файлового кеша по отметке, а остальные данные из SQL-источника. Для каждого обращения к кубу анализируется отметка открытия, если она попадает в прокешированные данные, то используются только данные кеша, если не попадает, то отметка достраивается и запрашивается из стандартного куба, а данные размещаются во временной таблице. Для включения частичного кеш ограничьте отметку куба в консоли управления кешированием данных многомерных кубов для конкретного куба.
Возможно использование частичного кеша для ограничения куба по параметрам – построить частичный кеш по отметке, соответствующей заданным параметрам куба. В этом случае можно отключить дозапрос данных из SQL-источника указанием параметра настройки PartialRestricted=true в консоли управления кешированием данных многомерных кубов для конкретного куба или в файле settings.xml или в системном реестре для сервера.
Аддитивный кеш
Позволяет кешировать данные в кубе не сразу, а дополнять по отметке по мере обращения к ним. При открытии прокешированного куба запоминается, по какой отметке производились открытия, и если отметка открытия шире ранее запрошенной, то производится дозапрос данных из источника. Кеш куба изначально создаётся пустым. Для включения аддитивного кеша задайте значение параметра AdditiveCache=force в консоли управления кешированием данных многомерных кубов для конкретного куба или в файле settings.xml или в системном реестре для сервера. Для кубов с управляющими измерениями и альтернативных иерархий аддитивный кеш включен по умолчанию.
Хранимые свёртки
Позволяют хранить агрегированные данные, которые получаются при агрегации фиксированных измерений. Хранимые свёртки обеспечивают ускоренную работу на больших объёмах данных инструментов отчётности. При первом обращении по заданной фиксированной отметке производится расчёт данных, при последующих используется уже построенная хранимая свёртка. Для включения хранимых свёрток задайте значение параметра AllowConv=true в консоли управления кешированием данных многомерных кубов для конкретного куба или в файле settings.xml или в системном реестре для сервера. Данные хранимых свёрток относятся к переменному кешу.
Быстрая агрегация данных ROLAP
Существует возможность применения комбинированного режима ROLAP и MOLAP, когда данные источника не кешируются, а хранятся в быстрой СУБД колоночной архитектуры. При этом извлечение данных из такого источника производится весьма быстро, в особенности при исключении ряда измерений, а для применения агрегации по уровням иерархии применяется быстрая алгоритмика подсистемы MOLAP. Для использования такого варианта обработки данных задайте параметр InMemAggr в консоли управления кешированием данных многомерных кубов для конкретного куба или в файле settings.xml или в системном реестре для сервера. Для всех кубов задайте значение all или укажите идентификаторы отдельных кубов.
В этом случае после извлечения данных из ROLAP к ним будет применена MOLAP-агрегация. Кеширование данных куба в этом случае не должно производиться.
Совместный доступ
Механизм разделяемого кеша обеспечивает совместную кластерную работу InMemory MOLAP-серверов на общих данных. Для включения совместного доступа задайте параметр SharedAccess=true в файле settings.xml или в системном реестре для сервера. В результате файлы кеша во всех использующих процессах открываются в разделяемом режиме. При этом используются блокировки и специальная файловая сигнализация для того, чтобы изменённые в одном процессе данные были своевременно актуализированы другими процессами, использующих эти данные.
Для реализации совместной работы нескольких InMemory MOLAP-серверов с общими данными следует организовать общий файловый ресурс, размещённый на сетевом диске по протоколу NFS, предоставить InMemory MOLAP-серверам полный доступ к нему и указать соответствующий удалённый каталог в качестве используемого пути к данным параметром DataDir в файле settings.xml или в системном реестре для сервера.
Особенности поддержки различных инструментов платформы
Файловых кеш поддерживает различные объекты продукта «Форсайт. Аналитическая платформа».
Представление-куб
В файловом кеше поддерживаются представления-кубы, которые построены над кешированным стандартным кубом. При этом не производится повторного кеширования либо какого-то запоминания данных – все преобразования, в частности по сокращению числа измерений или фиксации отметки, производятся алгоритмически надо прокешированными многомерными данными. Таким же способом поддерживаются цепочки из представлений-кубов: в качестве источника может выступать не только кешированный стандартный куб, но и другой представление-куб.
Альтернативные иерархии
Применение к кубу альтернативной иерархии требует перевычисления агрегатов, основываясь на тех же исходных данных. Если исходные данные куба были прокешированы в файловом кеше, и задан один из хранимых способов расчёта агрегации, то первое применение альтернативной иерархии вызовет построение хранимых агрегатов, что займёт время, а последующие будут его использовать без лишних задержек. Заранее рассчитать агрегаты по альтернативным иерархиям возможно, например, путём создания и открытия экспресс-отчётов на соответствующих данных. Следует учесть, что для использования альтернативных иерархий по умолчанию система будет использовать аддитивный кеш. Это связано с тем, что альтернативная иерархия может содержать элементы измерений, которых нет в основном представлении куба, и для дозапроса данных по этим элементам требуется режим аддитивного кеша.
Дубли в альтернативных иерархиях
В файловом кеше реализована поддержка дублей элементов измерений, когда в иерархии присутствуют два элемента справочника с одним и тем же ключом, включенные в различные уровни иерархии. В этом случае обеспечивается корректная обработка как при вычислении значений агрегатов, так и при итерировании данных такой матрицы. Следует заметить, что физически дублированные ячейки хранятся в кеше один раз, и «размножение» их значений по координатным дублям производится виртуализировано без физического копирования значений.
Информационные панели
Информационные панели с целью оптимизации при работе в колоночных СУБД могут исключать измерения, применяя при этом для ROLAP функции группировки на уровне SQL. При файловом кешировании источника данных возникает необходимость поддержки такого режима в MOLAP. Поддержка исключения измерений реализована построением и применением хранимых свёрток над прокешированной матрицей исходных данных. По исключаемым измерениям определяется полная отметка, после чего размерность матрицы понижается, и производится перерасчёт соответствующих значений. При повторном запросе на исключение измерений хранимые свёртки будут быстро переиспользоваться без пересчёта. Если на таком кубе описана иерархическая агрегация, то она будет считаться «на лету» поверх посчитанной свёртки.
Кубы с непривязанными измерениями
Непривязанным измерением в кубе считается такое, которое не связано с чем-то при настройке куба, и для данных оно делает декартово произведение со всеми точками. То есть, при использовании всё выглядит так, что точки в кубе реально размножаются во столько раз, сколько элементов в непривязанном измерении или их декартовом произведении. При файловом кешировании такого куба реализована специальная схема виртуализации непривязанного измерения: в самом кеше хранится сокращённый набор «настоящих» измерений, а фантомные координаты достраиваются на ходу. Таким образом, кешируется только необходимый минимум данных, а остальные вычисляются на их основе при обращении.
Ограничения работы с файловым кешем
При работе с файловым кешем имеются следующие ограничения:
не поддерживаются единицы измерения, заданные на кубе;
не поддерживается агрегация измерения фактов;
атрибутный выход куба запрещено кешировать;
в информационных панелях при исключении измерений, должна задаваться одинаковая функция агрегации по всем измерениям;
не производится кеширование истории изменений, вложений и комментариев. Работа с этой функциональностью производится через дополнительные запросы к SQL-источнику, данные доступны только при обращениях через BI-сервер;
не поддерживается использование хранимых свёрток на основе частичного или аддитивного кеша, а также поверх не полностью прокешированных агрегатов;
нельзя кешировать справочники, если на них настроены ABAC-правила доступа.
Ограничения ассоциативного анализа:
необходимо использовать полностью хранимую агрегацию при работе с ассоциативным анализом;
источником данных для ассоциативного анализа является стандартный куб;
ассоциативный анализ может выдавать данные ячеек, которые были удалены в кубе. Для учёта удаления ячеек нужно включить режим AllowAssoc=full в консоли управления кешированием данных многомерных кубов для конкретного куба или в файле settings.xml или в системном реестре для сервера. При таких настройках вычисление может производиться медленнее.