To cache data in Foresight Analytics Platform, In-Memory is applied. In-Memory is a subsystem that enables data loading from sources (cube caching), data local storage, quick multiuser access and high performance. Caching enables to avoid sending request each time the data sample from DBMS is required. The following repository objects support In-Memory caching:
All cube types, except calculated (virtual cubes and cube views use source cache).
Time series databases.
ADOMD cubes.
All dictionary types except for calendar dictionary, composite dimension of virtual cube and scenario dimension of modeling container.
IMPORTANT. If repository objects caching is used for dictionaries, repository objects caching settings are not taken into account when In-Memory data caching is used. The In-Memory data caching has a higher priority than repository objects caching.
Data is stored in file cache. Cache stores values from definite point and coordinates identifying point binding to data source. Files containing the data currently in use are mapped to computer memory. Memory paging mechanism provides a possibility to work in limited RAM with almost unlimited size of data stored in files. In case of out-of-memory state, data loading/downloading is page-by-page.
On caching dictionaries, attribute values corresponding to dictionary elements are saved to the file cache. It is taken into account whether dictionary has parameters (the cache is created for each set of parameters), elements have validity period (MDM dictionaries), various users have access permissions to elements.
When the In-Memory mechanism is used, a special structure with source data is loaded to RAM memory. Further data processing (creating data slice, filtering, aggregation, sorting, and so on) is executed in the RAM memory, without addressing data source. Thus, the platform response time is reduced and user work interactivity increases. Cache provides incremental data processing where if some cells are modified, then only related with those cells data is recalculated and not the whole source. On working user access permissions to data are taken into account. Data segments that are set up on creating a role model for business process modeling and for Foresight Budgeting.
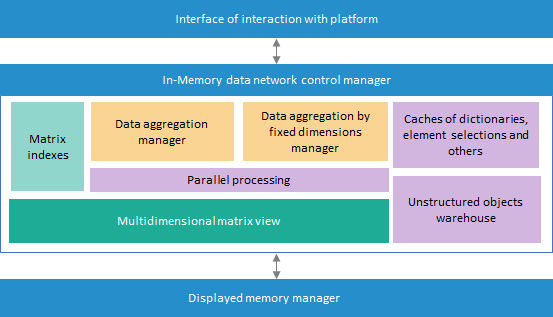
The In-Memory mechanism architecture looks as follows:
Architecture of In-Memory includes:
Interface of communication with Platform. It provides to the platform tools the data actually in use.
In-Memory data network control manager. It fully controls cache: creating and working with files, interaction with displayed memory manager, controlling data structures, allocating computer resources on executing various operations and other functions.
Displayed memory manager. It provides the quickest possible loading of required file fragment to RAM using operating system possibilities, search of required data in RAM to work with it.
To use the In-Memory data caching:
Fill in the InMem section:
In the Settings.xml file.
NOTE. The InMem section must be filled in on all client computers if the desktop application is used, or on BI server if the web application is used.
Select the repository object in the object navigator.
Enable object caching by selecting the Cacheable Object checkbox:
On the Cache tab in object properties in the desktop application.
In the object context menu in the web application.
NOTE. In the web application caching can be enabled on for cubes and time series databases.
After executing the operations, the In-Memory caching of the selected repository object is used. BI server applies dictionaries data caching which cache was enabled in the desktop application. When an object is worked with in the desktop and web applications, common cache is used if cache location paths specified in client computer and BI server settings match. The path to the folder with stored cache files is set on BI server or on all users' client computers using the DataDir parameter in system registry settings and in the Settings.xml file. By default, cache is created in the following folders:
Windows. C:\ProgramData\Foresight\Foresight Analytics Platform\inmem_data.
Linux. /var/tmp/inmem_data.
NOTE. Users that will work with cache must have read and write permissions to specified folders.
After data is changed and saved, updated data will be in the cache of the computer used for work. To update cache on computers of other users of the Foresight Analytics Platform desktop application, click the Update Cache button on the Cache tab in the object properties. To update cache of cubes and time series databases in the web application, select the Update Cache in the object context menu. On updating, cache is cleared and recreated.
The In-Memory shared cache enables the user to work with cached data when several Foresight Analytics Platform instances are started in desktop and web applications. If, on installing BI server, BI server cluster is created, common cache is used for shared use by several users on the In-Memory data caching.
To use shared cache:
Make sure that the In-Memory data caching is used, and cache location paths specified in client computer and BI server settings match.
Execute one of the operations:
Create the SharedAccess parameter with the True value:
In the Settings.xml file:
<...>
<Key Name="InMem">
<Key Name="UseInMem" Value="true"/>
<Key Name="DataDir" Value="C:\ProgramData\Foresight\Foresight Analytics Platform\inmem_data\"/>
<Key Name="MemLimitMb" Value="6000"/>
<Key Name="SharedAccess" Value="true"/>
</Key>
</...>
NOTE. If shared cache must be used on several BI servers or client computers, parameter value is set in settings of each BI server or client computer.
Place the file named shared.access without subfolders to the cache folder.
After executing the operations the shared cache is used for working with cached data on simultaneous startup of several instances of Foresight Analytics Platform.
The current implementation has the following constraints and features when working with data caching:
Cache is not used, if working with time series database is executed in the Analytical Queries (OLAP) tool, and the Attributes display version is enabled.
Cache created for time series databases will not be applied on working in the Time Series Analysis tool.
If any structure modifications are made in source dimensions (set of attributes is changed, new elements are added, hierarchy of existing elements changes and other modifications), for further correct work it is necessary to update cache.
Values by calculated facts of standard cube are not cached.
It is impossible to create cache, if cube has several sources, and the same dimension is linked in one of them and is not bound in others.
On creating cache, aggregations are calculated for default cube display option. For other display options, aggregation is calculated on the first request.
On editing cached dictionary, the current cache is reset and a new cache is created on the next dictionary call.
On caching parameterized dictionary, dictionary caches are created with each parameter sets in use.
On caching dictionaries with specified access permissions, dictionary caches corresponding to access permissions of each user are created.
Working with dictionaries cache in development environment is supported only via the IDimInstance interface.
Working with cache is available only inside one started platform instance.
See also: