Подготовка и развёртывание отказоустойчивого кластера
В этой статье:
Схема архитектуры развёртывания
Подготовка среды для продукта «Форсайт. Мобильная платформа»
Подготовка кластера системы Ceph
Подготовка кластера Kubernetes (k8s)
Подготовка к запуску продукта «Форсайт. Мобильная платформа»
Кластеры используются для распределения трафика, поддержки баз данных, хранения файлов и бизнес-приложений в сети. Для обеспечения горизонтального масштабирования всех компонентов системы реализован новый подход к развертыванию кластера.
Преимущества нового подхода:
использование новых средств развертывания и обслуживания компонентов кластера без простоя системы для регламентных работ;
использование бесплатного программного обеспечения с возможностью платной поддержки;
поддержка современной распределённой файловой системы Ceph;
быстрая установка и удобные механизмы обслуживания продукта «Форсайт. Мобильная платформа»;
удобный графический интерфейс Rancher для диагностики текущего состояния программного обеспечения.
Схема архитектуры развёртывания
Основные этапы схемы развёртывания отказоустойчивого кластера, которые приведены в данной статье:
Подготовка среды для продукта «Форсайт. Мобильная платформа»;
Подготовка к запуску продукта «Форсайт. Мобильная платформа»;
Запуск продукта «Форсайт. Мобильная платформа».
Обобщенная схема архитектуры развертывания отказоустойчивого кластера:
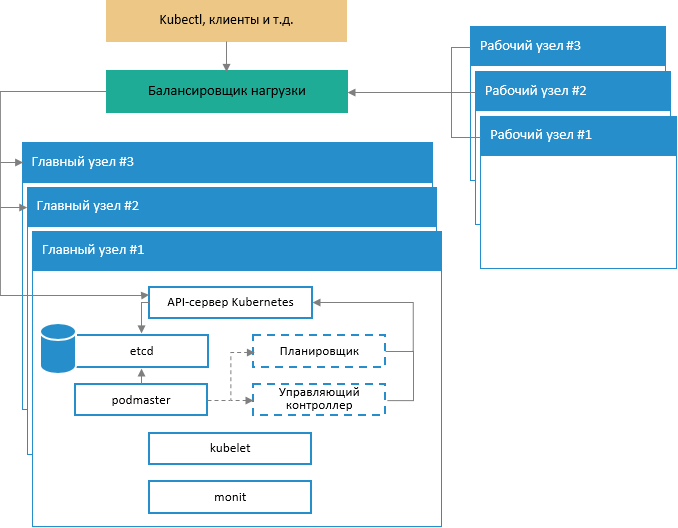
На схеме представлена работа системных сервисов Kubernetes на главных узлах кластера, а также взаимодействие главных узлов с рабочими узлами и входящими запросами через специальные сервисы с поддержкой балансировки нагрузки.
Схема обеспечения отказоустойчивости управляющей части кластера:
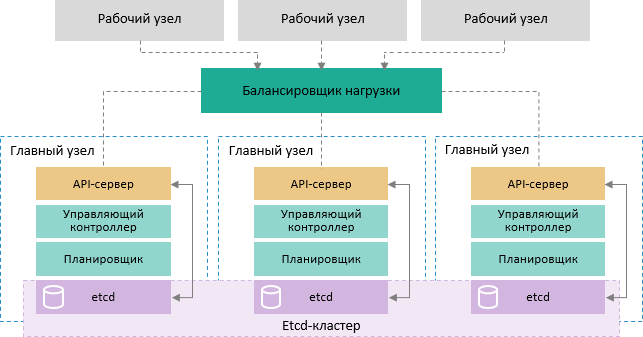
Примечание.
Каждый главный узел в кластере содержит следующие процессы и компоненты:
1. kube-apiserver. Единственная
точка управления для кластера. Команда kubectl взаимодействует напрямую
через API;
2. kube-controller-manager.
Процесс управления состоянием кластера с помощью контроллеров;
3. kube-scheduler. Процесс
планирования задач на всех доступных узлах в кластере;
4. etcd. База данных на основе
пар «ключ-значение», в которой хранятся сведения о состоянии всех
компонент кластера.
Технические требования
Для создания минимальной конфигурации отказоустойчивого кластера требуется шесть виртуальных или аппаратных узлов. Каждый узел должен иметь минимум два сетевых интерфейса.
Три узла являются главными и используются исключительно для управления кластером, контроля состояния его целостности, планирования и запуска контейнеров с приложениями в модулях кластера. К главным узлам предъявляются следующие системные требования:
конфигурация: 4-х ядерный процессор, 8 ГБ оперативной памяти, 50 ГБ жесткий диск;
ОС: Linux Ubuntu 16.04;
Три узла являются рабочими и несут основную нагрузку (на данных узлах исполняются модули с приложениями). К рабочим узлам предъявляются следующие системные требования:
конфигурация: 8-ми ядерный процессор, 8 ГБ оперативной памяти, два жестких диска объемом 100 ГБ и 150 ГБ;
ОС: Linux Ubuntu 16.04.
Настраиваемая программная среда: Docker, Kubernetes и Ceph (при необходимости).
Подключение директории /var/lib/docker должно быть выполнено на отдельный диск или LVM.
Примечание. В дальнейшем описании для главных узлов используются названия kn0, kn1, kn2, для рабочих узлов - kn3, kn4, kn5.
Подготовка среды для продукта «Форсайт. Мобильная платформа»
Подготовка узлов
Для подготовки узлов:
- На всех узлах создайте пользователя fmpadmin, от имени которого будет происходить установка и управление будущим кластером:
sudo useradd -m -d
/home/fmpadmin -s /bin/bash fmpadmin
# Задание пароля пользователю fmpadmin
sudo passwd fmpadmin
Добавьте пользователя fmpadmin в sudo users, для того чтобы всякий раз при использовании команды sudo не приходилось вводить пароль:
echo "fmpadmin
ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/fmpadmin
chmod 0440 /etc/sudoers.d/fmpadmin
Отключите SWAP-раздел на всех узлах кластера, так как kubelet не поддерживает работу со SWAP:
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
swapoff –all
Важно.
Если все узлы кластера являются виртуальными машинами под управлением
VMware, то на каждый узел установите пакет vmware-tools:
sudo apt-get
install -y open-vm-tools
Установите базовые пакеты и среду Docker Community Edition:
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl
software-properties-common
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg |
sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu
$(lsb_release -cs) stable"
sudo apt-get update
Для просмотра списка доступных к установке версий Docker Community Edition используйте команду:
sudo apt-cache madison docker-ce
Пример результата выполнения команды:
###On each of your
machines, install Docker. Version 18.09.9 is recommended, but
1.11, 1.12, 1.13, 17.03 and 19.03.5 are known to work as well.
### Latest validated Docker version: 18.09.x
## Install docker ce.
sudo apt-get update && sudo apt-get install docker-ce=5:18.09.9~3-0~ubuntu-xenial
Добавьте пользователя fmpadmin в группу docker:
sudo usermod -aG docker fmpadmin
Выполните настройку файла /etc/hosts одинаково на всех узлах:
127.0.0.1 localhost
<host-ip-address> kn0.our.cluster kn0
<host-ip-address> kn1.our.cluster kn1
<host-ip-address> kn2.our.cluster kn2
<host-ip-address> kn3.our.cluster kn3
<host-ip-address> kn4.our.cluster kn4
<host-ip-address> kn5.our.cluster kn5
# The following lines are desirable for IPv6 capable hosts
#::1 localhost ip6-localhost
ip6-loopback
#ff02::1 ip6-allnodes
#ff02::2 ip6-allrouters
Сгенерируйте SSH-ключ для пользователя fmpadmin на узле kn0:
От имени пользователя fmpadmin выполните команду:
ssh-keygen
В консоль будет выведен диалог, например:
Enter file in which to save the key (/home/user/.ssh/id_rsa):
Нажмите клавишу ENTER. Далее система предложит ввести кодовую фразу для дополнительной защиты SSH-подключения:
Enter passphrase (empty for no passphrase):
Пропустите этот и следующий шаги. Для этого нажимайте клавишу ENTER. В результате будет создан SSH-ключ.
Создайте конфигурационный файл для SSH:
vim ~/.ssh/config
Содержимое конфигурационного файла:
Host kn0
Hostname kn0
User fmpadmin
Host kn1
Hostname kn1
User fmpadmin
Host kn2
Hostname kn2
User fmpadmin
Host kn3
Hostname kn3
User fmpadmin
Host kn4
Hostname kn4
User fmpadmin
Сохраните изменения и выйдите из редактора.
Измените разрешения на файл:
chmod 644 ~/.ssh/config
Соберите публичные ключи всех узлов (выполняется на узле kn0 под пользователем fmpadmin):
$ ssh-keyscan kn0 kn1 kn2 kn3 kn4 >> ~/.ssh/known_hosts
Добавьте созданный SSH-ключ на все узлы:
ssh-copy-id kn1
ssh-copy-id kn2
ssh-copy-id kn3
ssh-copy-id kn4
Примечание. При запросе системой пароля введите пароль пользователя fmpadmin.
Настройте NTP-cервер для синхронизации времени между узлами:
sudo apt-get install -y ntp ntpdate
cp /etc/ntp.conf /etc/ntp.conf.orig
Примечание. Настройку проводите для второго сетевого интерфейса, предназначенного только для межузлового трафика.
На узле kn0:
cat << EOF > /etc/ntp.conf \
server 127.127.1.0 prefer \
fudge 127.127.1.0 stratum 10 \
interface ignore wildcard \
interface listen <адрес, который будет использоваться для ntp
server lan ip> \
EOF
systemctl restart ntp.service
На остальных узлах:
server <адрес ntp server lan ip на узле kn0
> iburst
restrict default
interface ignore wildcard
interface listen <your ntp client lan ip>
sudo systemctl restart ntp.service
В результате будет выполнена подготовка узлов.
Установка пакета Heartbeat
Целевые узлы для пакета Heartbeat - три рабочих сервера с одним общим виртуальным IP-адресом. Непрерывная доступность сервисов обеспечивается с помощью пакета Heartbeat.
Примечание. Установка и настройка пакета Heartbeat выполняется на узлах kn3, kn4 и kn5.
Для установки и настройки пакета Heartbeat:
Установите и настройте Heartbeat:
apt-get update && apt-get -y install heartbeat && systemctl enable heartbeat
Примечание. Все три сервера делят один IP-адрес - <main external cluster ip>. Этот виртуальный IP-адрес будет перемещаться между серверами, поэтому включите параметр net.ipv4.ip_nonlocal_bind, чтобы разрешить привязку системных служб к нелокальному IP-адресу.
Добавьте эту возможность в файл /etc/sysctl.conf для узлов kn3, kn4, kn5:
# echo ‘net.ipv4.ip_nonlocal_bind=1’ >>
/etc/sysctl.conf
# sysctl -p
Создайте файл /etc/ha.d/authkeys. В этом файле Heartbeat хранит данные для взаимной аутентификации, файл должен быть одинаковым на обоих серверах:
# echo -n securepass | md5sum
bb77d0d3b3f239fa5db73bdf27b8d29a
# Где securepass – пароль для Heartbeat.
# Cкопируйте полученную хеш-сумму в буфер обмена.
kn3
$ sudo vi /etc/ha.d/authkeys
auth 1
1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a
kn4
sudo vi /etc/ha.d/authkeys
auth 1
1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a
kn5
sudo vi /etc/ha.d/authkeys
auth 1
1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a
Проверьте, что файл /etc/ha.d/authkeys доступен только пользователю Root:
Kn3# sudo chmod 600 /etc/ha.d/authkeys
Kn4# sudo chmod 600 /etc/ha.d/authkeys
Kn5# sudo chmod 600 /etc/ha.d/authkeys
Создайте основные файлы конфигурации для Heartbeat на выбранных серверах (для каждого сервера файл будет незначительно отличаться):
Создайте файл /etc/ha.d/ha.cf на узлах kn3, kn4, kn5.
Примечание. Для получения параметров узлов для конфигурации запустите uname -n на всех трех серверах. Также используйте имя вашей сетевой карты вместо ens160.
Kn3# vi /etc/ha.d/ha.cf
# keepalive: how many
seconds between heartbeats
#
keepalive 2
#
# deadtime: seconds-to-declare-host-dead
#
deadtime 10
#
# What UDP port to
use for udp or ppp-udp communication?
#
udpport 694
bcast ens160
mcast ens160 225.0.0.1 694 1 0
ucast ens160 <main kn3 ip>
# What interfaces to
heartbeat over?
udp ens160
#
# Facility to use for
syslog()/logger (alternative to log/debugfile)
#
logfacility local0
#
# Tell what machines
are in the cluster
# node nodename
... -- must match uname -n
node kn3
node kn4
node kn5
kn4# vi /etc/ha.d/ha.cf
# keepalive: how many
seconds between heartbeats
#
keepalive 2
#
# deadtime: seconds-to-declare-host-dead
#
deadtime 10
#
# What UDP port to
use for udp or ppp-udp communication?
#
udpport 694
bcast ens160
mcast ens160 225.0.0.1 694 1 0
ucast ens160 <main kn4 ip>
# What interfaces to
heartbeat over?
udp ens160
#
# Facility to use for
syslog()/logger (alternative to vlog/debugfile)
#
logfacility local0
#
# Tell what machines
are in the cluster
# node nodename
... -- must match uname -n
node kn3
node kn4
node kn5
kn5# vi /etc/ha.d/ha.cf
# keepalive: how many
seconds between heartbeats
#
keepalive 2
#
# deadtime: seconds-to-declare-host-dead
#
deadtime 10
#
# What UDP port to
use for udp or ppp-udp communication?
#
udpport 694
bcast ens160
mcast ens160 225.0.0.1 694 1 0
ucast ens160 <main kn5 ip>
# What interfaces to
heartbeat over?
udp ens160
#
# Facility to use for
syslog()/logger (alternative to vlog/debugfile)
#
logfacility local0
#
# Tell what machines
are in the cluster
# node nodename
... -- must match uname -n
node kn3
node kn4
node kn5
Создайте файл /etc/ha.d/haresources. В нём указывается общий виртуальный IP-адрес и задаётся, какой узел является главным по умолчанию. Файл должен быть одинаковым на всех узлах:
Kn3# vi /etc/ha.d/haresources
Kn3 <main virtual cluster ip>
Kn4# vi /etc/ha.d/haresources
Kn3 <main virtual cluster ip>
Kn5# vi /etc/ha.d/haresources
Kn3 <main cluster ip> ### здесь и выше kn3 =
hostname узла, выбранного “главным” по умолчанию для heartbeat.
Запустите службы Heartbeat на всех узлах и проверьте, что на узле kn3 установлен заявленный виртуальный IP-адрес:
Kn3# systemctl restart heartbeat
Kn4# systemctl restart heartbeat
Kn5# systemctl restart heartbeat
kn1# ip a s
ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc
pfifo_fast state UP group default qlen 1000
link/ether xx:xx:xx:xx:xx:xx brd ff:ff:ff:ff:ff:ff
inet <main kn3 ip>/24
valid_lft forever preferred_lft
forever
inet <main cluster ip>/24
Проверьте доступ по main cluster ip:
nc -v <main cluster ip> 22
Connection to x.x.x.x 22 port [tcp/*] succeeded!
SSH-2.0-OpenSSH_7.2p2 Ubuntu-4ubuntu2.7
Установка и настройка пакета Heartbeat завершена.
Подготовка кластера системы Ceph
Установка Ceph
Для установки и настройки Ceph:
Установите python:
apt-get update && apt-get install -y python python-pip parted
Примечание. Все команды необходимо выполнять на одном узле.
Выполните команды:
sudo fdisk -l /dev/sdb
sudo parted -s /dev/sdb mklabel gpt mkpart primary xfs 0% 100%
sudo mkfs.xfs -f /dev/sdb
sudo fdisk -s /dev/sdb
sudo blkid -o value -s TYPE /dev/sdb
Разверните Ceph сначала на узле kn0:
sudo -H pip install ceph-deploy
ceph-deploy new kn0
В текущей директории появится файл ceph.conf.
Отредактируйте ceph.conf в соответствии с файлом, входящим в поставку ./fmp_k8s_v1/ceph/ceph.conf:
[global]
fsid = a997355a-25bc-4749-8f3a-fb07df0f9105 - замените на значение
из вашего файла ceph.conf
mon_initial_members = kn1,kn0,kn3 - замените на имена ваших узлов
mon_host = 10.30.217.17,10.30.217.20,10.30.217.23 - замените на
адреса ваших узлов
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
# Our network address
public network = 10.30.217.0/24 - замените на адрес вашей сети
rbd default features = 3
[mon.kn0]
host = kn0 - замените на имя вашего узла
mon addr = 10.30.217.20:6789 - замените
на адрес вашего узла
[mon.kn1]
host = kn1 - замените на имя вашего узла
mon addr = 10.30.217.17:6789 - замените
на адрес вашего узла
[mon.kn3]
host = kn3 - замените на имя вашего узла
mon addr = 10.30.217.23:6789 - замените
на адрес вашего узла
# added below config
[osd]
osd_journal_size = 512
osd_pool_default_size = 3
osd_pool_default_min_size = 1
osd_pool_default_pg_num = 64
osd_pool_default_pgp_num = 64
# timeouts for OSD
osd_client_watch_timeout = 15
osd_heartbeat_grace = 20
osd_heartbeat_interval = 5
osd_mon_heartbeat_interval = 15
osd_mon_report_interval = 4
[mon]
mon_osd_min_down_reporters = 1
mon_osd_adjust_heartbeat_grace = false
mon_client_ping_timeout = 15.000000
Примечание. Все имена и адреса узлов замените вашими.
Установите пакеты Ceph сразу на всех узлах:
ceph-deploy install kn0 kn1 kn2 kn3 kn4 kn5
Данная операция займёт продолжительное время.
Настройте мониторинг узла kn1:
# вместо create-initial можно указать узел
ceph-deploy mon create-initial
Данная команда создаст ключ роли мониторинга. Для получения ключа выполните команду:
ceph-deploy gatherkeys kn1
Добавление OSD-узлов
После установки Ceph на все узлы добавьте OSD-роли в кластер Ceph. Для хранения данных и журнала они будут использовать раздел /dev/sdb на диске.
Проверьте на всех узлах, доступен ли раздел диска /dev/sdb:
ceph-deploy disk list kn3 kn4 kn5
Удалите таблицы разделов на всех узлах:
ceph-deploy disk zap kn3 /dev/sdb
ceph-deploy disk zap kn4 /dev/sdb
ceph-deploy disk zap kn5 /dev/sdb
Данная команда удалит все данные из раздела /dev/sdb на узлах OSD Ceph.
Подготовьте и активируйте все OSD-узлы, убедитесь в отсутствии ошибок:
ceph-deploy osd create kn3 --data /dev/sdb
The last output line should be: Host kn3 is now ready for osd use.
ceph-deploy osd create kn4 --data /dev/sdb
The last output line should be: Host kn4 is now ready for osd use.
ceph-deploy osd create kn5 --data /dev/sdb
The last output line should be: Host kn5 is now ready for osd use.
Отправьте admin keys и конфигурацию на все узлы:
ceph-deploy admin kn0 kn1 kn2 kn3 kn4 kn5
Измените права на key file. Выполните на всех узлах команду:
sudo chmod 644 /etc/ceph/ceph.client.admin.keyring
В результате будет создан кластер Ceph.
Важно. Необходимо явно добавить Ceph Manager Service.
Для добавления Ceph Manager Service:
На узле kn0 (ceph-admin) выполните команду:
ceph auth get-or-create mgr.kn1 mon 'allow profile mgr' osd 'allow *' mds 'allow *'
Команда вернёт значение mgr keyring. Скопируйте его и переходите к следующему шагу.
Выполните команду:
ssh (monitoring role node, e.g. kn1)
sudo –i
mkdir /var/lib/ceph/mgr/ceph-kn1
Затем отредактируйте файл vi /var/lib/ceph/mgr/ceph-kn1/keyring. Вставьте в него значение mgr keyring из предыдущего шага.
Выполните команду:
chmod 600 /var/lib/ceph/mgr/ceph-kn1/keyring
chown ceph-ceph –R /var/lib/ceph/mgr/
Запустите ceph-mgr менеджер:
sudo systemctl start ceph-mgr.target
Проверьте статус кластера Ceph:
sudo ceph –s
cluster:
id: a997355a-25bc-4749-8f3a-fb07df0f9105
health: HEALTH_OK
services:
mon: 3 daemons, quorum kn1,kn3, kn0
mgr: kn1(active)
mds: cephfs-1/1/1 up {0=kn1=up:active}, 2 up:standby
osd: 3 osds: 3 up, 3 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 147 GiB / 150 GiB avail
pgs:
Если кластер вернул ответ HEALTH_OK, то кластер работает.
Создание сервера метаданных
Для использования CephFS требуется, как минимум, один сервер метаданных. Для его создания выполните команду:
ceph-deploy mds create {ceph-node}
Развертывание Ceph-менеджеров
Ceph-менеджер работает в активном режиме или в режиме ожидания. Развертывание дополнительных Ceph-менеджеров гарантирует, что в случае выхода из строя одного из Ceph-менеджеров другой Ceph-менеджер сможет продолжить выполнение операций без перерывов в обслуживании.
Для развертывания дополнительных Ceph-менеджеров:
Выполните команду:
ceph-deploy mgr create node2 node3
Выполните следующие команды для проверки работы Ceph:
получение состояние кластера Ceph:
sudo ceph -s
просмотр всех существующих пулов, занимаемого пространства;
sudo ceph df
просмотр состояния OSD-узлов:
sudo ceph osd tree
Создайте отдельный пул kube для кластера Kubernetes (k8s):
sudo ceph osd pool create kube 32 32
>> pool 'kube' created // The two ’30’s are important – you
should review the ceph documentation for Pool, PG and CRUSH configuration
to establish values for PG and PGP appropriate to your environment
Проверьте количество реплик для пула:
$ sudo ceph osd pool get kube size
size: 3
Проверьте количество placement groups для пула:
$ sudo ceph osd pool get kube pg_num
pg_num: 32
Свяжите созданный пул с rbd-приложенем для его использования в качестве устройства RADOS:
$ sudo ceph osd pool application enable kube rbd
>>enabled application 'rbd' on pool 'kube'
- Создайте отдельного пользователя для пула kube и сохраните ключи, требуемые для доступа k8s к хранилищу:
$ sudo ceph auth get-or-create client.kube mon
'allow r' osd 'allow rwx pool=kube'
[client.kube]
key = AQC6DX1cAJD3LRAAUC2YpA9VSBzTsAAeH30ZrQ==
mkdir ./to_etc
sudo ceph auth get-key client.admin > ./to_etc/client.admin
sudo cp ./to_etc/client.admin /etc/ceph/ceph.client.admin.keyring
sudo chmod 600 /etc/ceph/ceph.client.admin.keyring
Приведите содержимое файла к виду:
[client.admin]
key = AQCvWnVciE7pERAAJoIDoxgtkfYKMnoBB9Q6uA==
caps mds = "allow
*"
caps mgr = "allow
*"
caps mon = "allow
*"
caps osd = "allow
*"
sudo ceph auth get-key client.kube > ./to_etc/ceph.client
sudo cp ./to_etc/ceph.client /etc/ceph/ceph.client.kube.keyring
sudo chmod 644 /etc/ceph/ceph.client.kube.keyring
- Приведите содержимое файла к виду:
[client.kube]
key = AQCvWnVciE7pERAAJoIDoxgtkfYKMnoBB9Q6uA==
caps mds = "allow
*"
caps mgr = "allow
*"
caps mon = "allow
*"
caps osd = "allow
*"
Установка и настройка распределенной файловой системы Ceph завершена.
Подготовка кластера Kubernetes (k8s)
Все команды на главных узлах Kubernetes выполняйте от имени пользователя root. Ввиду возможных проблем с неправильной маршрутизацией трафика в обход iptables при использовании ОС RHEL / CentOS 7, убедитесь, что для net.bridge.bridge-nf-call-iptables в конфигурации sysctl установлено значение 1.
На каждом узле выполните:
От имени пользователя root внесите изменения в system для правильной работы сетей в k8s:
cat >>/etc/sysctl.d/kubernetes.conf<<EOF
net.bridge.bridge-nf-call-ip6tables = 0
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl –system
apt-get update && apt-get install -y apt-transport-https
curl
Добавьте в систему официальный Kubernetes GPG ключ:
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
Добавьте Kubernetes репозиторий:
cat <<EOF > /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/kubernetes-xenial main
EOF
Установите значение /proc/sys/net/bridge/bridge-nf-call-iptables равным 1 для корректной работы CNI (Container Network Interface). Для этого проверьте текущее значение:
cat /proc/sys/net/bridge/bridge-nf-call-iptables
Если текущее значение равно 0, то выполните команду:
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables
На узле kn0 от имени пользователя root инициализируйте кластер Kubernetes:
Перейдите в домашнюю директорию пользователя fmpadmin: /home/fmpadmin. Распакуйте архив, содержащий скрипты и yaml-файлы на одном управляющем узле:
% tar –xvzf ./fmp_k8s_v<номер версии>.tar
Перейдите в директорию с распакованными скриптами:
% cd ./ fmp_k8s_v<номер версии>/
Перейдите в поддиректорию rke:
% cd ./rke
Выполните команду:
% ls –lh ./
Будет отображён список файлов в текущей директории:
-rwxr-xr-x 1 root root
388 Mar 26 20:44 fmpclust.yml
-rw-rw-r-- 1 root root 1.3K
Mar 26 20:48 ReadMe.txt
-rwxr-xr-x 1 root root 36M
Mar 28 14:54 rke
Переместите или скопируйте файл rke в директорию /usr/local/bin/:
% mv ./rke /usr/local/bin/
Установите права на файл rke:
% chmod 755 /usr/local/bin/rke
Отредактируйте содержимое файла fmpclust.yml в соответствии с вашей конфигурацией:
vi ./fmpclust.yuml
nodes:
- address: m1
user: ваш пользователь
role: [controlplane,etcd]
- address: m2
user: ваш пользователь
role: [controlplane,etcd]
- address: m3
user: ваш пользователь
role: [controlplane,etcd]
- address: w1
user: ваш пользователь
role: [worker]
- address: w2
user: ваш пользователь
role: [worker]
- address: w3
user: ваш пользователь
role: [worker]
services:
kubelet:
extra_binds:
- "/lib/modules:/lib/modules"
extra_args:
node-status-update-frequency: 10s
etcd:
snapshot: true
creation: 6h
retention: 24h
kube-api:
extra_args:
default-not-ready-toleration-seconds:
30
default-unreachable-toleration-seconds:
30
kube-controller:
extra_args:
node-monitor-period: 5s
node-monitor-grace-period: 40s
pod-eviction-timeout: 30s
authentication:
strategy: x509
# sans:
# - "10.99.255.254"
network:
plugin: flannel
Примечание. 10.99.255.254 — общий IP-адрес кластера серверов (если применимо); m1, m2, m3 - имена главных узлов Kubernetes; w1,w2, w3 - имена рабочих узлов Kubernetes; ваш пользователь - пользователь, от имени которого будет осуществляться взаимодействие между узлами (fmpadmin).
Разверните и проинициализируйте кластер:
% rke up --config fmpclust.yml
Операция занимает значительное количество времени и сопровождается подробным выводом в консоль всех этапов развёртывания кластера.
Если всё сделано правильно, то развёртывание кластера пройдет успешно, и в консоль сервера будет выведена строка:
INFO[0103] Finished building Kubernetes cluster successfully
Если возникли ошибки, запустите rke up повторно с ключом debug для вывода подробной информации:
% rke -d up --config fmpclust.yml
После инициализации кластера в текущей директории рядом с файлом fmpclust.yml появится файл kube_config_fmpclust.yml. Переместите или скопируйте его в профиль пользователя. Это позволит пользователю взаимодействовать с кластером. Выполняйте данную операцию от имени пользователя fmpadmin:
% mkdir ~/.kube
% cd ./ fmp_k8s_v<номер версии>/rke/
% cp ./kube_config_fmpclust.yml ~/.kube/config
% sudo chown -R fmpadmin:fmpadmin /home/fmpadmin/.kube
В результате будет установлен и инициализирован кластер Kubernetes (k8s). Проверьте его работу:
Проверьте версию сервера и клиента k8s:
% kubectl version - -short
В консоль будет выведено:
Client Version: v1.13.5
Server Version: v1.13.5
Проверьте статус компонентов k8s:
% kubectl get cs
В консоль будет выведено:
NAME STATUS
MESSAGE ERROR
scheduler Healthy
ok
controller-manager Healthy ok
etcd-0 Healthy
{"health": "true"}
etcd-1 Healthy
{"health": "true"}
etcd-2 Healthy
{"health": "true"}
Установка Rancher
Rancher - это программное обеспечение для удобного управления кластером k8s.
Для установки и настройки Rancher:
Создайте на узле kn4 папку для хранения информации Rancher:
% sudo mkdir –p /opt/rancher
Запустите Rancher c монтированием на хост:
% sudo docker run -d --restart=unless-stopped -p 8180:80 -p 8446:443 -v /opt/rancher:/var/lib/rancher rancher/rancher:stable
Откройте браузер и перейдите по адресу https://ip-address-of-kn0:8446, где ip-address-of-kn0 - это IP-адрес узла kn0. Установите пароль для роли администратора Rancher в веб-интерфейсе:
Добавьте созданный кластер в Rancher. Нажмите кнопку «Add Cluster»:

Выберите тип добавления. Нажмите «Import»:

- Укажите название и описание для добавляемого кластера и нажмите «Create»:

Скопируйте последнюю команду на странице:
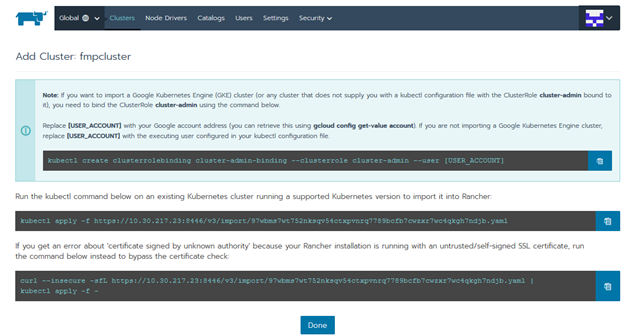
Общий вид команды:
% curl --insecure -sfL https://<server ip>:8446/v3/import/dtdsrjczmb2bg79r82x9qd8g9gjc8d5fl86drc8m9zhpst2d9h6pfn.yaml | kubectl apply -f -
Где <server ip> - это IP-адрес узла.
Выполните скопированную команду в консоли узла kn0. В консоль будет выведено:
namespace/cattle-system created
serviceaccount/cattle created
clusterrolebinding.rbac.authorization.k8s.io/cattle-admin-binding
created
secret/cattle-credentials-3035218 created
clusterrole.rbac.authorization.k8s.io/cattle-admin created
deployment.extensions/cattle-cluster-agent created
daemonset.extensions/cattle-node-agent created
Ожидайте запуск системы:

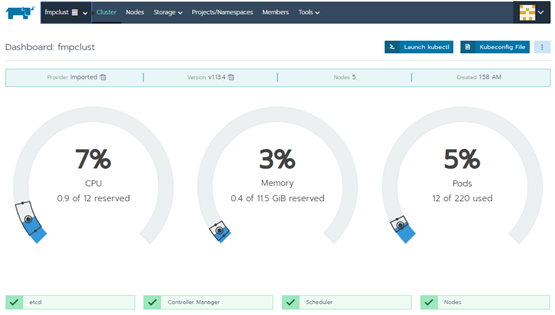
После окончания инициализации статус кластера изменится на Active:
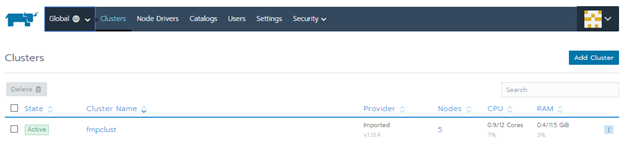
Общее состояние кластеров:
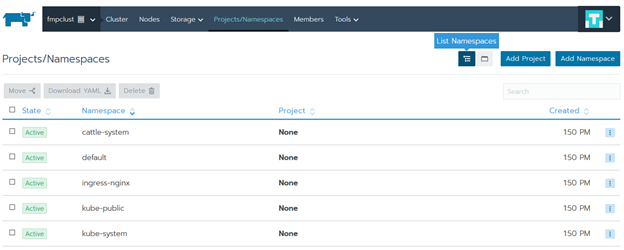
Перейдите в раздел Projects/Namespaces и создайте Project для платформы:
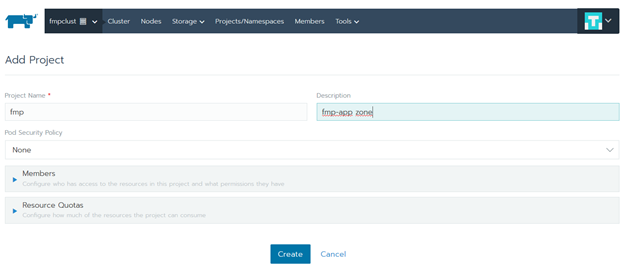
Нажмите «Add Project». Заполните поле «Project Name», добавьте описание в поле «Description» и нажмите «Create»:
Нажмите «Add Namespace». Заполните поле «Name» и нажмите «Create»:
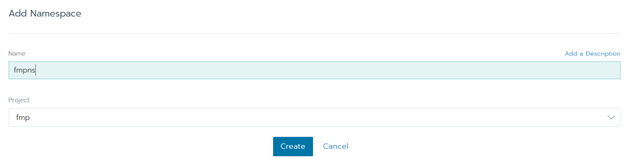
Настройка через графический веб-интерфейс завершена. Перейдите к консоли узлов.
Подготовка к запуску продукта «Форсайт. Мобильная платформа»
Откройте консоль одного из главных узлов Kubernetes от имени пользователя fmpadmin. В домашнюю директорию пользователя был загружен архив с образами контейнеров приложения, а также архив с набором скриптов и yaml-файлов для запуска приложения в среде Kubernetes.
Скопируйте архив fmp_v<номер версии>.tgz на рабочие узлы кластера.
Загрузите образы контейнеров в систему:
docker load -i fmp_v<номер версии>.tgz
Примечание. Данный архив распакуйте на всех рабочих узлах кластера.
После успешного импорта удалите архив.
На одном управляющем узле распакуйте архив, содержащий скрипты и yaml-файлы:
% tar –xvzf ./fmp_k8s_v<номер версии>.tar
Перейдите в директорию с распакованными скриптами:
% cd ./ fmp_k8s_v<номер версии>
Отредактируйте содержимое yaml-файла ./storage/ceph-storage-ceph_rbd.yml:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-rbd
provisioner: kubernetes.io/rbd
parameters:
monitors: 10.30.217.17:6789, 10.30.217.20:6789, 10.30.217.23:6789
adminId: admin
adminSecretName: ceph-secret
adminSecretNamespace: "kube-system"
pool: kube
userId: kube
userSecretName: ceph-secret-kube
В строке monitors укажите IP-адреса или DNS-имена узлов Ceph-кластера с установленной ролью мониторинга. Для просмотра на каких именно узлах установлена эта роль используйте команду:
% sudo ceph -s
Результат выполнения команды, например:
cluster:
id: a997355a-25bc-4749-8f3a-fb07df0f9105
health: HEALTH_OK
services:
mon: 3 daemons, quorum kn1,kn0,kn3
mgr: kn3(active), standbys: kn0
osd: 4 osds: 4 up, 4 in
Строка mon в разделе services указывает на имена узлов с установленной ролью мониторинга.
Добавьте secret-keys распределённого файлового хранилища Ceph в Kubernetes:
Получите ключ администратора Ceph:
% sudo ceph --cluster
ceph auth get-key client.admin
>> AQCvBnVciE8pERAAJoIDoxgtkfYKZnoBS9R6uA==
Скопируйте его в буфер обмена.
Важно. При копировании и последующей вставке ключа в команду для добавления в настройки Kubernetes пробелы не допускаются!
Добавьте полученный ключ в секреты Kubernetes, явно указав его в команде:
% kubectl create secret
generic ceph-secret --type="kubernetes.io/rbd" \
--from-literal=key='AQCvWnVciE7pERAAJoIDoxgtkfYKMnoBB9Q6uA=='
--namespace=kube-system
Результат выполнения команды:
secret/ceph-secret created
Создайте отдельный пул для узлов Kubernetes в кластере Ceph. Созданный пул будет использоваться в RBD на узлах:
% sudo ceph --cluster ceph osd pool create kube 32 32
Создайте клиентский ключ. В кластере Ceph включена аутентификация Ceph:
% sudo ceph --cluster ceph auth get-or-create client.kube mon 'allow r' osd 'allow rwx pool=kube'
Получите ключ client.kube:
% sudo ceph --cluster ceph auth get-key client.kube
Создайте новый секрет в пространстве имён проекта:
% kubectl create secret
generic ceph-secret-kube --type="kubernetes.io/rbd"
\
--from-literal=key='AQC6DX1cAJD3LRAAUC2YpA9VSBzTsAAeH30ZrQ==' --namespace=fmpns
После добавления обоих секретов можно переходить к запуску продукта «Форсайт. Мобильная платформа».
Запуск продукта «Форсайт. Мобильная платформа»
Выполните скрипты в следующем порядке в директории fmp_k8s_v<номер версии>:
create-rbds.sh. Скрипт создает и подготавливает тома для приложения fmp в Ceph (используется в случае наличия Ceph);
fmp_k8s_storage_inst.sh. Скрипт выполняется при использовании распределённого файлового хранилища Ceph. Ранее в статье было показано, как настроить Ceph-кластер;
Перейдите в директорию volumes. Откройте на редактирование скрипт set_my_monitors.sh и замените в нём IP-адреса на адреса ваших узлов с ролью Ceph Monitor в строках:
export mon1='192.1.1.1'
export mon2='192.1.1.2'
export mon3='192.1.1.3'
В директории volumes выполните скрипт set_my_monitors.sh;
Вернитесь в директорию выше;
fmp_k8s_volumes_inst.sh. Скрипт создает и подготавливает тома для использования приложением fmp;
fmp_k8s_configmap_inst.sh. Скрипт создает карту переменных;
fmp_k8s_services_inst.sh. Скрипт настраивает сервисы для взаимодействия компонентов приложения fmp между собой;
fmp_k8s_deployments_inst.sh. Скрипт настраивает условия для запуска компонентов приложения fmp;
Init pod. При первом запуске происходит инициализация внутренних сервисов ФМП, это требует запуска отдельного Init pod. Как только Init pod выполнит все необходимые процедуры, он переходит в состояние Succeeded.
Вернитесь к веб-интерфейсу и убедитесь, что все необходимые объекты созданы, а контейнеры приложения запущены без ошибок:
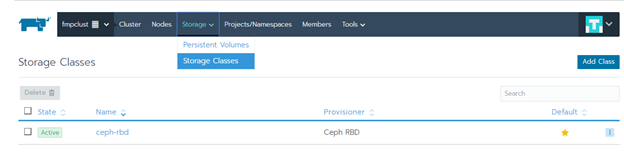
Проверьте наличие подключённого хранилища. Перейдите в раздел «Storage > Storage Classes»:
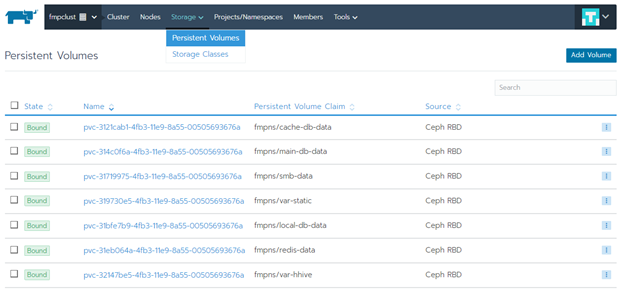
Проверьте наличие созданных Persistent Volumes. Перейдите в раздел «Storage > Persistent Volumes»:
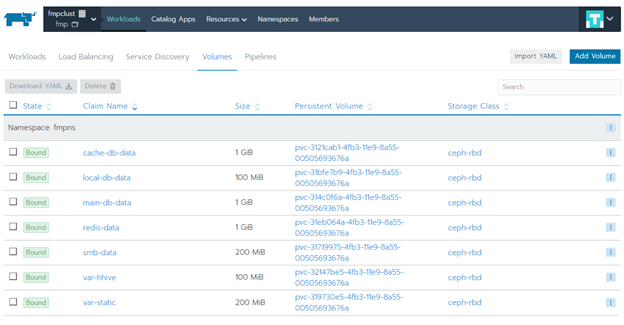
Затем выберите приложение fmp и перейдите в раздел «Workbooks» на вкладку «Volumes»:
Проверьте наличие Config Maps - списка загруженных переменных. Перейдите в раздел «Resources»:
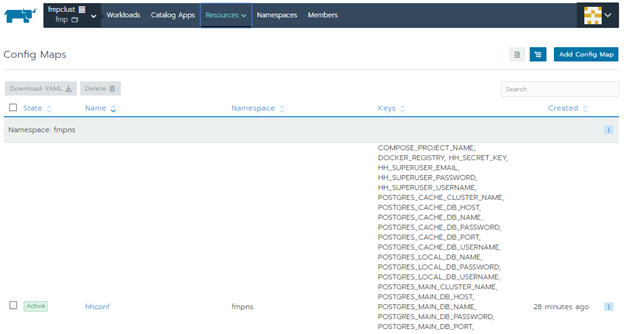
Перейдите в раздел «Workbooks» и убедитесь, что создались элементы на вкладках:
Workloads:
Service Discovery:
Load Balancing успешно перешёл в состояние Active:
В результате будет подготовлен и развёрнут отказоустойчивый кластер и приложение «Форсайт. Мобильная платформа».
Откройте браузер и перейдите по IP-адресу <main cluster ip>, который был указан при настройке HAProxy. Будет открыта страница авторизации в приложении «Форсайт. Мобильная платформа»:
Перечень портов, используемых для работы кластера
Порты, используемые Kubernetes для функционирования главных узлов кластера, приведены в следующей таблице:
| Протокол | Направление | Диапазон портов | Назначение | Использование |
TCP |
inbound |
6443 | Kubernetes API server | all |
TCP |
inbound |
2379-2380 | etcd server client API | kube-apiserver, etcd |
TCP |
inbound |
10250 | kubelet API | self, сontrol plane |
TCP |
inbound |
10251 | kube-scheduler | self |
TCP |
inbound |
10252 | kube-controller-manager | self |
Порты, используемые Kubernetes для функционирования рабочих узлов кластера, приведены в следующей таблице:
| Протокол | Направление | Диапазон портов | Назначение | Использование |
TCP |
inbound |
10250 |
kubelet API |
self, сontrol plane |
TCP |
inbound |
30000-32767 | nodePort Services |
all |
RKE (Rancher Kebernetes Engine) узел - Порты для исходящих соединений приведены в следующей таблице:
| Протокол | Источник | Диапазон портов | Назначение | Описание |
TCP |
RKE-узел |
22 |
все узлы, указанные в файле конфигурации кластера |
настройка узлов через SSH, выполняемая RKE |
TCP |
RKE -узел |
6443 |
управляющие узлы |
Kubernetes API server |
Примечание. В данной статье роли главных узлов и etcd-узлов объединены.
Порты для входящих соединений управляющих узлов приведены в следующей таблице:
| Протокол | Источник | Диапазон портов | Описание |
TCP |
any that consumes Ingress services | 80 | ingress controller (HTTP) |
TCP |
any that consumes Ingress services | 443 | ingress controller (HTTPS) |
TCP |
rancher nodes | 2376 | Docker daemon TLS port used by Docker Machine (only needed when using Node Driver/Templates) |
TCP |
etcd nodes; control plane nodes; worker nodes |
6443 | Kubernetes API server |
UDP |
etcd nodes; |
8472 | canal/flannel VXLAN overlay networking |
TCP |
control plane node itself (local traffic, not across nodes) | 9099 | canal/flannel livenessProbe/readinessProbe |
TCP |
control plane nodes | 10250 | kubelet |
TCP |
control plane node itself (local traffic, not across nodes) | 10254 | ingress controller livenessProbe/readinessProbe |
TCP/UDP |
any source that consumes NodePort services | 30000-32767 | NodePort port range |
Порты для исходящих соединений управляющих узлов приведены в следующей таблице:
| Протокол | Назначение | Диапазон портов | Описание |
TCP |
rancher nodes | 443 | rancher agent |
TCP |
etcd nodes | 2379 | etcd client requests |
TCP |
etcd nodes | 2380 | etcd peer communication |
UDP |
etcd nodes; control plane nodes; worker nodes |
8472 | canal/flannel VXLAN overlay networking |
TCP |
control plane node itself (local traffic, not across nodes) | 9099 | canal/flannel livenessProbe/readinessProbe |
TCP |
etcd nodes; control plane nodes; worker nodes |
10250 | kubelet |
TCP |
control plane node itself (local traffic, not across nodes) | 10254 | ingress controller livenessProbe/readinessProbe |
Порты для входящих соединений рабочих узлов приведены в следующей таблице:
| Протокол | Источник | Диапазон портов | Описание |
TCP |
any network that you want to be able to remotely access this node from |
22 | remote access over SSH |
TCP |
any that consumes Ingress services | 80 | ingress controller (HTTP) |
TCP |
any that consumes Ingress services | 443 | ingress controller (HTTPS) |
TCP |
rancher nodes | 2376 | Docker daemon TLS port used by Docker Machine (only needed when using Node Driver/Templates) |
UDP |
etcd nodes; |
8472 | canal/flannel VXLAN overlay networking |
TCP |
worker node itself (local traffic, not across nodes) | 9099 | canal/flannel livenessProbe/readinessProbe |
TCP |
control plane nodes | 10250 | kubelet |
TCP |
worker node itself (local traffic, not across nodes) | 10254 | ingress controller livenessProbe/readinessProbe |
TCP/UDP |
any source that consumes NodePort services | 30000-32767 | NodePort port range |
Порты для исходящих соединений рабочих узлов приведены в следующей таблице:
| Протокол | Назначение | Диапазон портов | Описание |
TCP |
rancher nodes | 443 | rancher agent |
TCP |
control plane nodes |
6443 |
Kubernetes API server |
UDP |
etcd nodes; control plane nodes; worker nodes |
8472 |
canal/flannel VXLAN overlay networking |
TCP |
worker node itself (local traffic, not across nodes) |
9099 |
canal/flannel livenessProbe/readinessProbe |
TCP |
worker node itself (local traffic, not across nodes) |
10254 |
ingress controller livenessProbe/readinessProbe |