To reveal hidden facts and relationships in large data sets, use the Data Mining tool.
The Data Mining tool is used for processing and meaningful interpretation of large data arrays.
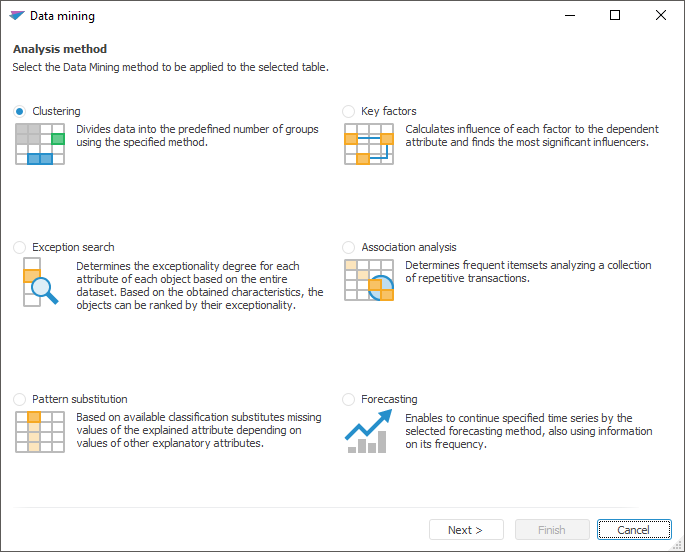
Key features:
Dividing objects or observations into the specified number of groups based on proximity of their attribute values.
Determining "exceptionality degree" for each attribute of each object based on the total amount of data.
Filling missing values of one attribute depending on the values of other attributes based on the existing classification
Revealing most significant factors, revealing a degree of influence of each factor on a dependent variable.
Determining often occurring adjacent element sets based on the set of repeated transactions
Continuing the specified time series by the selected forecasting method by using information about its frequency pattern.
To start working, see the Start Working with the Data Mining tool article.